bzt wrote:
Nice! Could you please add
micropython to the measurement mix?
micropython wasn't playing well with the benchmark suite, so I had to make some manual changes to support it:
Code:
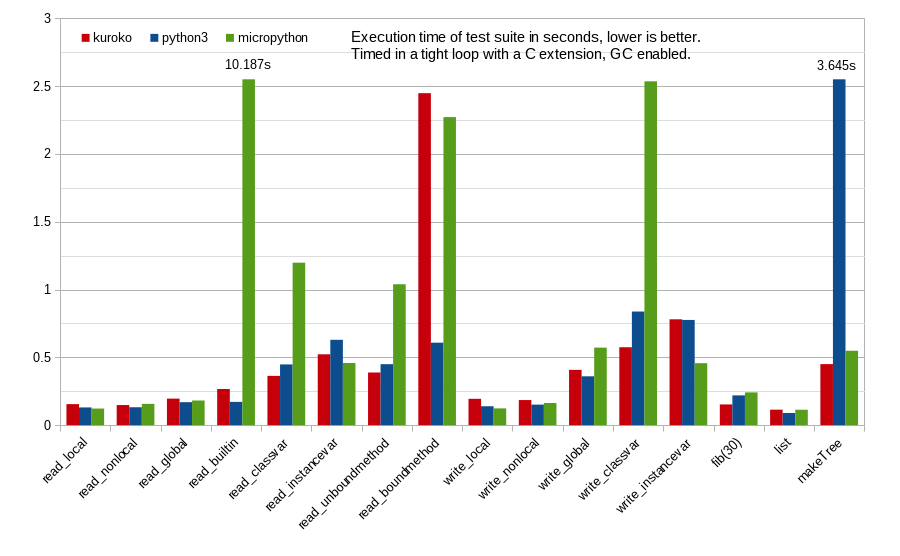
0.1083040237426758 read local
0.1457369327545166 read nonlocal
0.1717119216918945 read global
10.10828304290772 read builtin
1.090549945831299 read classvar
0.4275898933410645 read instancevar
1.047213077545166 read unboundmethod
2.001680850982666 read boundmethod
0.1163589954376221 write local
0.1476550102233887 write nonlocal
0.5679929256439209 write global
2.420825958251953 write classvar
0.4025170803070068 write instancevar
0.2225830554962158 fib(30)
0.1101620197296143 list append
0.5477221012115479 makeTree
(* This was run on a faster machine from the original benchmarking, but also the timing mechanism may not be as accurate due to differences in the "timeit" implementation used; I'll rerun numbers on the same machine and make a new graph tomorrow - it's quite late here.)
I ran the benchmark a couple of times, and that builtin read time is really surprising - I can't imagine builtins are really that slow to retrieve, so my guess would be Micropython is optimizing very specifically for the case where builtin functions are
called while this test is dereferencing "oct" hundreds of thousands of times without calling it.
bzt wrote:
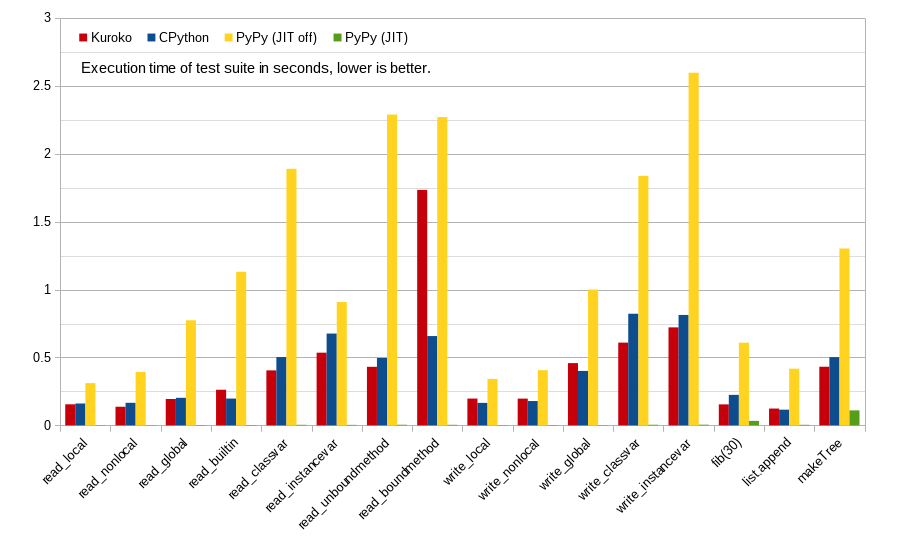
It looks like your optimization was very successful, there's only one test case (read_boundmethod) you should polish further, all the others are in par with CPython. Well done!
Allocations are the killer here! CPython's reference counting means it can easily recycle the same bound method object over and over - the test does hundreds of thousands of runs, each entailing a new allocation in Kuroko. There's a few places where CPython pulls tricks like this, like small tuples and lists. None of the other variable references involve object allocations - notably the assignment tests all assign "1" and small integer types are a primitive value stored directly in a stack reference cell in Kuroko.