bzt wrote:
moonchild wrote:
I understand that executable memory is a potential attack vector. However I stand by what I said: I don't think that's the most interesting potential attack vector;
Then you're thinking it wrong. Arbitrary code execution is the most serious attack vector, because it could lead to malicious activities. You might crash a computer with any bug, but in order to steal sensible data or spread a virus, you'd need arbitrary code execution. Privilege escalation and sandbox escaping has absolutely no use and are totally harmless without arbitrary code execution.
So, I was operating under the assumption that we are allowing untrusted code to run under the JIT. I think that's an interesting usage case and should be supported. You need some form of sandboxing, and VMs are very heavyweight. In an SASOS you don't have any other options, as you can't rely on CPU memory protections.
Which means that all an attacker needs in order to get arbitrary code execution is a codegen bug. Not a buffer overflow (though that will do just as well).
bzt wrote:
moonchild wrote:
Interpreters are easier to secure, yes; but usually a nonstarter for performance reasons.
I disagree. A properly written interpreter can be a lot faster than a badly written JIT.
An APL interpreter will beat most other implementations of most other programming languages. Beyond that, for other PL paradigms: I find that difficult to believe. The overhead of dispatch is
massive. Look, for instance, at
this series, which walks through building a toy JIT for brainfuck. Look in particular at this benchmark:
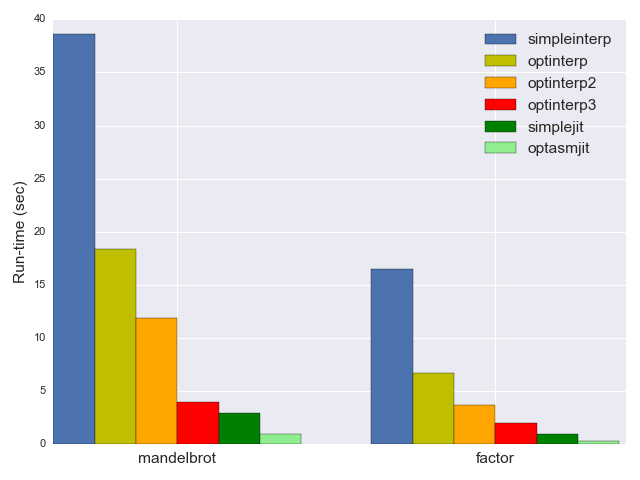
The optimized interpreter (bright red) is handily beaten by the most naive JIT (dark green). And this for brainfuck, a language where you need optimizations to turn INC;INC;INC;INC;INC;INC;INC;INC;INC;INC into ADD 10 (for example).
bzt wrote:
On the other hand are you familiar how
continuation-passing style threaded code was implemented in the '70s Forth interpreter?
Yes. (Though that technique almost certainly has worse performance than gcc-computed-goto ish strategies, because it has bad locality.)
bzt wrote:
Do you know why does the register-based
Dalvik run much faster than the stack-based JVM (even though they are both bytecode interpreters)?
Dalvik and hotspot (which I assume is what you mean by 'the stack-based JVM') are both JIT compilers.
I don't find that link particularly credible. The explanation of stack machines is wrong, and it claims that only register VMs can do CSE (???). Meanwhile wikipedia
says dalvik is 2-3x slower than hotspot.
bzt wrote:
Have you seen the performance measurements of
wasm3 using a continuation-passing style, register-based model?
I see that it proudly claims to be 4-5x slower than JITs :)
bzt wrote:
Plus performance is not everything. Sometimes stability is lot more important. For example if I had to pick a software for a space probe, I'd surely prefer stability over performance, without hesitation and I wouldn't regret that.
I 100% agree. 100%. Slow interpreters are awesome.
However, you probably want to have the
possibility of high-performance, native-efficiency (or close enough to) code on your OS. Which precludes using solely interpreters.
bzt wrote:
Yes, I've read it carefully, you explicitly mentioned "java programs", and not language.
Meaning, programs written in java...
bzt wrote:
moonchild wrote:
An implementation of the language absolutely can, however. There were bugs in the JVM.
The CVE-2020-2803 wasn't a bug in the JVM, it was a bug in the Bytebuffer built-in java class (which is part of the language btw). It's like having a bug in printf, neither the C code nor the compiler nor the ELF loader nor the ELF interpreter could be held responsible for that.
You are taking my words out of context. I addressed this:
moonchild wrote:
some the bugs also had to do with misuse of sun.misc.unsafe, which is not actually part of the language but an implementation detail of the standard library
sun.misc.unsafe is a set of explicitly unsafe libraries. They are not supported and not part of the java language proper.
bzt wrote:
A formally verified language implementation and proven code does not guarantee no bugs. For that you'd also need a formally verified and proven compiler, libraries and CPU (or VM) too
The compiler
is the language implementation. The libraries yes, of course you would have to formally verify. But that seems obvious: any libraries you use as part of your implementation are part of your implementation.
The CPU—yes, the CPU can have bugs. Formal verification is used extensively by CPU designers, which is part of the reason that CPUs tend to have
much fewer bugs than most other types of software. But the CPU is an interpreter which expresses asm's semantics in terms of physics, and our physical models are imperfect. However, a CPU bug would be likely to affect non-compiler code just as badly as compiler code so I don't think it's very relevant here.







